Introduction
Understanding probability and statistics often begins with the normal distribution, one of the most important concepts in data analysis. Among the many tools derived from it, the z inversa normal estandar plays a critical role in interpreting data, making predictions, and solving real-world problems across fields such as finance, engineering, and social sciences.
The z inversa normal estandar refers to the process of finding a z-score when you already know the probability. Instead of calculating the probability from a given z-value, you reverse the process. This concept is essential for tasks like determining confidence intervals, hypothesis testing, and percentile calculations.
In this comprehensive guide, you will learn what z inversa normal estandar means, how it works, why it matters, and how to apply it effectively. By the end, you will have a deep understanding of this concept along with practical insights that you can use immediately.
Understanding the Standard Normal Distribution
Before diving into the z inversa normal estandar, it is essential to understand the standard normal distribution. The standard normal distribution is a special type of normal distribution where the mean is zero and the standard deviation is one.
This distribution is symmetrical and forms the familiar bell-shaped curve. Each point on the curve represents a z-score, which indicates how many standard deviations a value is from the mean.
The importance of this distribution lies in its universality. This allows statisticians to use a single reference table or computational tool to solve a wide variety of problems.
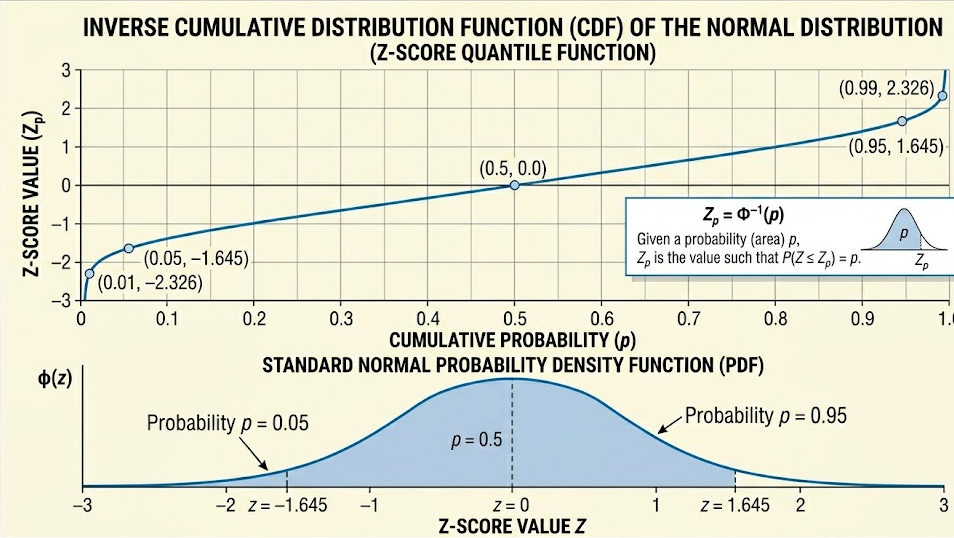
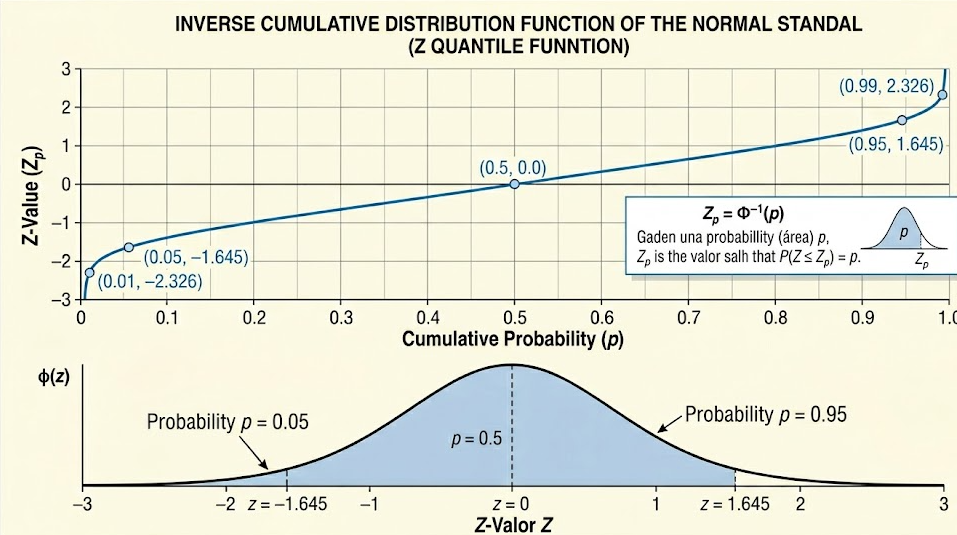
The probability associated with a z-score tells you the likelihood that a value falls below that point on the curve. However, in many real-world scenarios, we already know the probability and need to find the corresponding z-score. This is where the concept of z inversa normal estandar becomes essential.
Also Read:Newk’s Q Sandwich A Flavorful Favorite You Need to Try
What Is Z Inversa Normal Estandar
The z inversa normal estandar is the inverse function of the cumulative distribution function of the standard normal distribution. Instead of starting with a z-score and finding a probability, you start with a probability and determine the corresponding z-score.
In simpler terms, if you know that a certain percentage of data lies below a value, the z inversa normal estandar helps you find how many standard deviations that value is from the mean.
For example, suppose you know that 95 percent of the data falls below a certain point. Using the z inversa normal estandar, you can find the z-score that corresponds to that cumulative probability. This z-score is approximately 1.645 in many standard statistical contexts.
This concept is widely used in statistical inference, particularly in constructing confidence intervals and determining critical values for hypothesis tests.
Why Z Inversa Normal Estandar Matters
The importance of z inversa normal estandar lies in its practical applications. It allows analysts and researchers to make decisions based on probability thresholds.
In hypothesis testing, it helps determine whether to reject or accept a null hypothesis. By comparing a calculated test statistic with a critical value obtained using the inverse function, you can assess statistical significance.
In confidence interval estimation, it is used to find the margin of error. The z-score corresponding to a desired confidence level, such as 90 percent, 95 percent, or 99 percent, is obtained using the z inversa normal estandar.
In quality control, it helps define acceptable ranges and identify outliers. In finance, it is used to assess risk and calculate value at risk. In education, it helps interpret standardized test scores.
Without the z inversa normal estandar, many of these calculations would be significantly more complex or less precise.
Mathematical Concept Behind Z Inversa Normal Estandar
The z inversa normal estandar is mathematically defined as the inverse of the cumulative distribution function of the standard normal distribution.
If the cumulative distribution function is represented as Φ(z), then the inverse function is written as Φ⁻¹(p), where p represents the probability.
This inverse function does not have a simple algebraic expression. Instead, it is typically computed using numerical methods, statistical tables, or software tools.
Modern tools such as statistical software, spreadsheets, and programming languages provide built-in functions to calculate this value quickly and accurately.
Despite its computational complexity, the concept itself is straightforward. You are essentially finding the point on the horizontal axis of the normal curve that corresponds to a given cumulative probability.
Also Read:Latest Durostech Exploring the New Wave of Technology Innovation
How to Calculate Z Inversa Normal Estandar
To calculate the z inversa normal estandar, you need a probability value between zero and one. This value represents the cumulative probability up to a certain point on the standard normal curve.
Using a z-table, you can look up the probability and find the corresponding z-score. However, traditional tables are limited in precision and can be difficult to use for values not explicitly listed.
A more efficient approach is to use software tools. For example, spreadsheet programs provide functions that compute the inverse standard normal distribution directly. These functions take the probability as input and return the corresponding z-score.
For instance, if you input a probability of 0.975, the function will return approximately 1.96. This value is commonly used in constructing 95 percent confidence intervals.
The accuracy and convenience of these tools make them the preferred method for calculating z inversa normal estandar in modern statistical practice.
Practical Examples of Z Inversa Normal Estandar
To better understand how z inversa normal estandar works, consider a real-world scenario involving exam scores. Suppose test scores are normally distributed, and you want to find the score that separates the top 10 percent of students from the rest.
First, you identify the cumulative probability. Since you are interested in the top 10 percent, the cumulative probability is 0.90. Using the z inversa normal estandar, you find that the corresponding z-score is approximately 1.28.
This means that students who score 1.28 standard deviations above the mean are in the top 10 percent.
In another example, consider a manufacturing process where you want to determine the threshold below which only 5 percent of products fall. The cumulative probability is 0.05, and the corresponding z-score is approximately negative 1.645.
These examples demonstrate how the z inversa normal estandar helps translate probabilities into meaningful values in real-world contexts.
Applications in Confidence Intervals
Confidence intervals are one of the most common applications of z inversa normal estandar. A confidence interval provides a range of values within which a population parameter is likely to lie.
To construct a confidence interval, you need a critical z-value corresponding to the desired confidence level. This value is obtained using the z inversa normal estandar.
For a 95 percent confidence level, the critical z-value is approximately 1.96. This value ensures that the interval captures the true parameter 95 percent of the time under repeated sampling.
The ability to determine these critical values quickly and accurately makes the z inversa normal estandar an indispensable tool in statistical analysis.
Role in Hypothesis Testing
In hypothesis testing, the z inversa normal estandar is used to determine critical regions. These regions define the boundaries beyond which the null hypothesis is rejected.
For example, in a two-tailed test with a significance level of 0.05, you split the probability into two tails of 0.025 each. Using the z inversa normal estandar, you find the critical z-values that correspond to these probabilities.
If the test statistic falls outside these critical values, you reject the null hypothesis. Otherwise, you fail to reject it.
This process ensures that decisions are based on well-defined probability thresholds, reducing the risk of incorrect conclusions.
Also Read:Dubai Basketball vs Hapoel Tel Aviv B.C. Match Player Stats Complete Analysis
Common Mistakes and How to Avoid Them
One common mistake when using z inversa normal estandar is confusing cumulative probability with tail probability. It is important to understand whether the given probability represents the area to the left of a point or the area in the tail.
Another mistake is misinterpreting negative and positive z-scores. Remember that negative z-scores correspond to values below the mean, while positive z-scores correspond to values above the mean.
Using inaccurate tables or rounding values too early can also lead to errors. To avoid these issues, it is best to use reliable software tools and double-check calculations.
Understanding the context of the problem is crucial. Always ensure that the probability and z-score are interpreted correctly in relation to the distribution.
Tools for Computing Z Inversa Normal Estandar
Modern technology has made it easier than ever to compute z inversa normal estandar. Statistical software such as R, Python, and SPSS provides functions specifically designed for this purpose.
Spreadsheet applications also offer built-in functions that allow users to calculate inverse normal values with ease. These tools are widely accessible and require minimal technical knowledge.
Online calculators and educational platforms further simplify the process, making it possible for students and professionals alike to perform accurate calculations quickly.
The availability of these tools has significantly enhanced the accessibility and usability of statistical methods.
Real-World Use Cases
The z inversa normal estandar is used in a wide range of industries. In finance, it helps assess investment risk and determine thresholds for extreme losses. In healthcare, it is used in clinical trials to analyze treatment effectiveness.
In engineering, it plays a role in quality control and reliability testing. In marketing, it helps analyze consumer behavior and predict trends.
Educational institutions use it to interpret standardized test scores and establish grading curves. Governments use it in policy analysis and economic forecasting.
These diverse applications highlight the versatility and importance of the z inversa normal estandar in modern decision-making.
Conclusion
The z inversa normal estandar is a fundamental concept in statistics that allows you to move from probability to z-score. It plays a crucial role in confidence intervals, hypothesis testing, and a wide range of real-world applications.
By understanding how it works and how to apply it, you can make more informed decisions based on data. Whether you are a student, researcher, or professional, mastering this concept will enhance your analytical skills and improve your ability to interpret statistical results.
As data continues to drive decision-making in every field, the importance of tools like the z inversa normal estandar will only continue to grow.
FAQs
What does z inversa normal estandar mean?
It refers to finding a z-score from a given cumulative probability in the standard normal distribution.
When should I use z inversa normal estandar?
You should use it when you know the probability and need to determine the corresponding z-score, especially in confidence intervals and hypothesis testing.
Is z inversa normal estandar difficult to calculate?
It can be complex manually, but modern tools make it easy and accurate.
What is a common value obtained using z inversa normal estandar?
A commonly used value is 1.96, which corresponds to a 95 percent confidence level.
Can I calculate it without software?
Yes, using z-tables, but software is faster and more precise.
For more updates visit: blogify News